Analysis¶
The following provides a brief overview for the most common analysis required for each type of Monte Carlo calculation. The guides in Tutorials provide a step-by-step guide to analysing HANDE calculations and explain the reasoning behind the required analysis parameters.
HANDE includes a variety of scripts and utilities in the tools subdirectory. However,
these only provide a simple, command-line interface. A comprehensive python module,
pyhande, drives all the analysis. pyhande is extremely powerful for dealing
with complex analysis, data-driven investigation or bulk data analysis.
FCIQMC and CCMC¶
Fundamental Usage¶
QMC calculations print out data from a block of iterations (a ‘report loop’), the length of which is controlled by the mc_cycles input option. Care should be taken analysing this data and, in particular, producing accurate estimates of the errors in the means of the energy estimators. Almost all data is averaged over the report loop (see output for further details).
Note that no data is lost when quantities are summed over report loops, as the correlation length in the data is substantially longer than the length of the report loop (typically 10-20 iterations).
As the particle distribution at one iteration is not independent from the distribution at the previous iteration, estimators at each iteration are not independent. This correlation in the data needs to be taken into account when estimating standard errors. A simple and effective way of doing this is to use a blocking analysis [Flyvbjerg89].
The reblock_hande.py script (in the tools subdirectory) does this. Run
$ reblock_hande.py --help
to see the available options. Estimates for the shift and projected energy are typically obtained using
$ reblock_hande.py --start N out
respectively, where N is the starting iteration from which data should be blocked (i.e.
after the calculation has equilibrated) and out is the file to which the
calculation output was saved. Without –start option, this script automatically
estimates the appropriate N, so you usually don’t have to give N by yourself.
Note that reblock_hande.py can accept multiple output files for the case when a calculation is restarted as follows:
$ reblock_hande.py -m out1 out2 out3
More complicated analysis can be performed in python by
using the pyhande library — reblock_hande.py simply provides a convenient
interface for the most common analysis tasks.
Hybrid method¶
Hybrid method is different choice to estimate errors from blocking analysis, which is available as
$ reblock_hande.py -a hybrid out
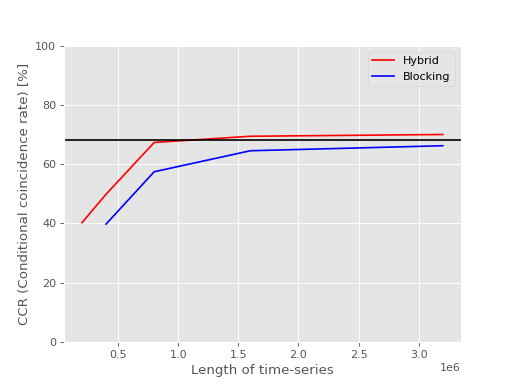
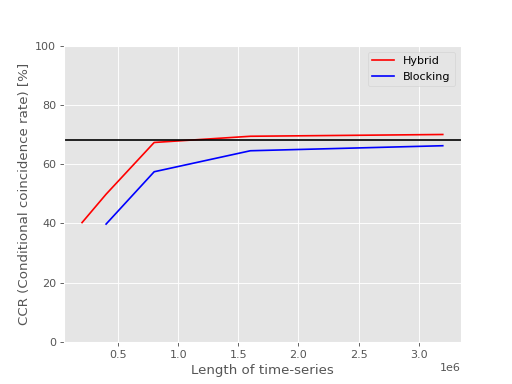
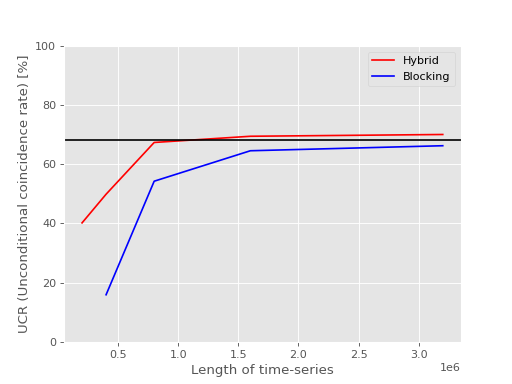
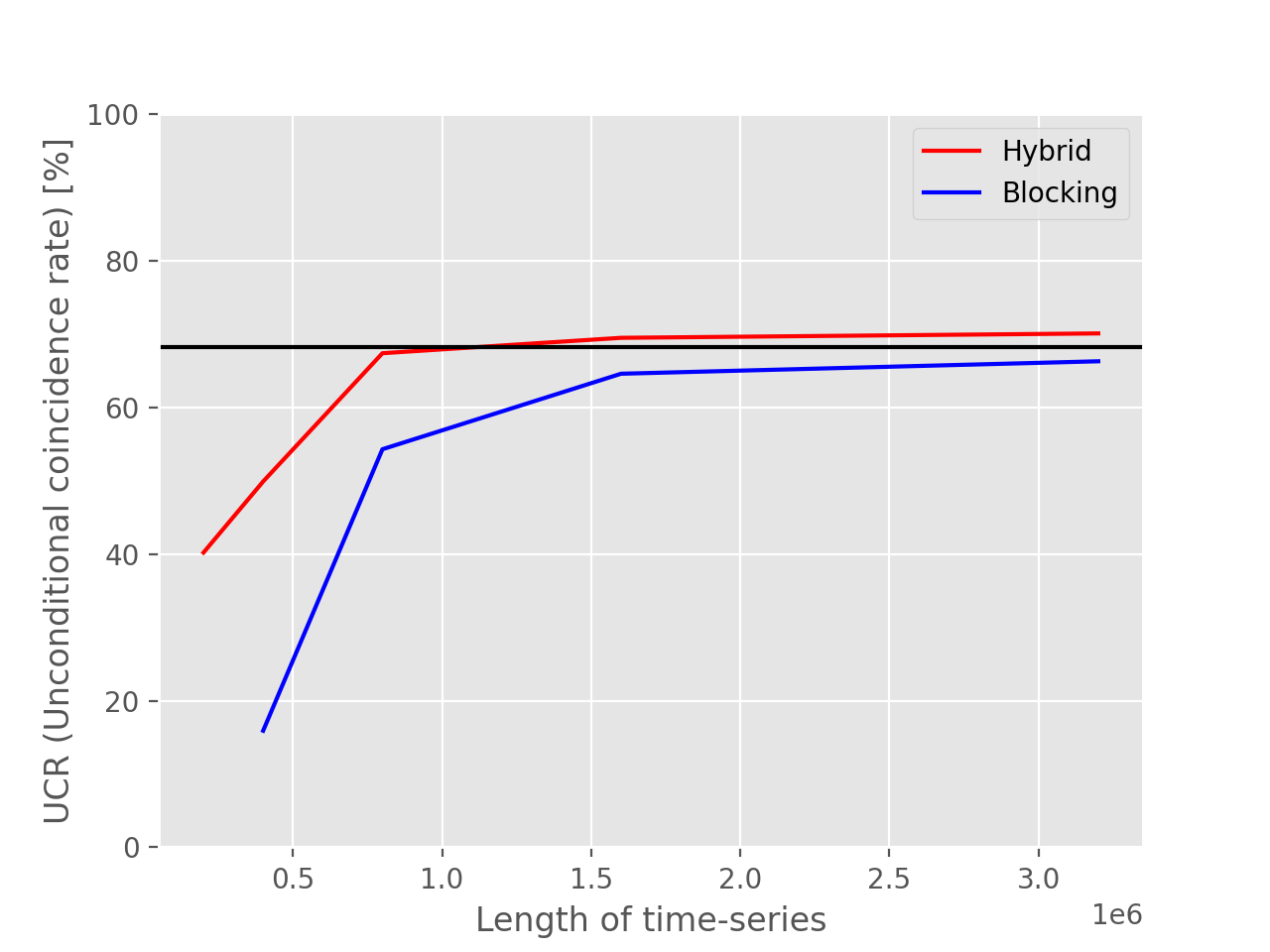
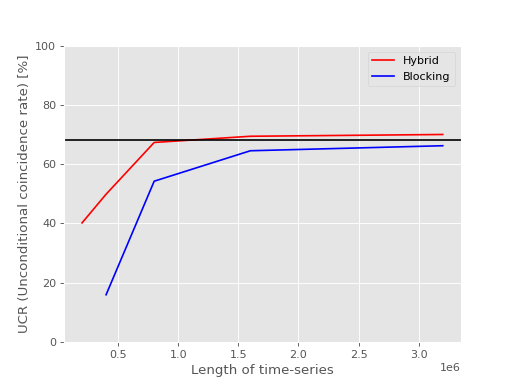
Our experiment has shown that hybrid method makes more reliable estimation of errors than blocking analysis: We prepared 1000 different CCMC-SD energy time-series for Nitrogen atom, with the same calculation settung but just different random seeds. Then, the energy means and the standard errors were obtained by hybrid method and blocking analysis, and it was examined how many means coincide with the CCSD energy within the range of the errors, respectively. The expected coincidence rate for 1 sigma accuracy is 68.27%. Thus, when the actual coincidence rate is closer to this percent, the post-analysis is more reliable.
We employed two types of coincidence rate to compare reliabilities, conditional coincidence rate (CCR) and unconditional coincidence rate (UCR), which are defined by
Here, ‘Total’ is the total number of post-analyses (=1000), ‘Failed’ is the number of post-analyses which fails to make an estimation of the error(*), and ‘Hit’ is the number of post-analyses which makes an estimation of the error and the energy mean coincides with the CCSD energy within the standard error. (*: e.g. ‘Shift is not started yet’ in the case of blocking method)
In the following figures, the former (latter) compares the CCRs (UCRs) obtained using hybrid method and blocking analysis for different lengths of time-series. Both figure shows that the CR of hybrid method is closer to 68.27% for short lengths of time-series.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
MSER minimization¶
There are two choices of method to estimate starting iterations, one is originally implemented in reblock_hande.py (here call it ‘WREE minimization’) and the other is the newly implemented, named ‘MSER minimization’. The new method is available as
$ reblock_hande.py -b mser_min out
These two methods are compared in a unpublished work, where it is established that WREE minimization discards extra much iterations, when length of time-series is large. On the other hand, MSER minimization always gives constant estimation of starting iterations, independent of length of time-series.
Canonical Total Energy MC¶
The configurations and resulting estimates in a canonical total energy
calculation are statistically independent and therefore no blocking analysis is
required. The analyse_canonical.py script is available in tools/canonical_energy/ which
performs the appropriate averaging and standard error analysis on the output file
using the pyhande suite.
DMQMC¶
No blocking analysis is required for the error analysis of DMQMC calculations
as estimates are averaged over statistically independent runs. The
finite_temp_analysis.py script in tools/dmqmc can be used to perform a
standard error analysis of the Monte Carlo data for a number of different observables.